谁是AI开源世界之王?
在人工智能的江湖,2015年是个关键时间节点,这一年之前和之后,似乎是两个截然不同的世界。
此前数年间,历经AI吊打在图像识别赛吊打传统算法、AI战胜世界围棋冠军、DeepMind“委身”谷歌等标志性事件,AI逐渐走出学术殿堂,开始用科幻般的“超能力”改变人们的认知。
从这一年开始,科技巨头的AI战事从暗战变为明局,AI也开始以前所未有的速度在全球爆发,逐渐演化成为如今AI格局的雏形。
每当我们提及第三次AI浪潮是如何复兴的,数据爆发、算力崛起已成为标准答案,而一股隐形却强大的力量却往往被视而不见。
而这股力量,不仅是使得AI再度兴盛的关键推手,也是科技巨头赢得AI话语权的“上甘岭”。
这股力量,就是开源。
当国外谷歌Facebook微软为升级迭代AI开源框架各显其能,国内以BAT领衔推进的AI开源项目亦在暗流涌动。
01 开源,黑客文化中诞生的奇迹
什么是开源的力量?这是包括AI在内的计算机发展史中,一个熠熠生辉的话题。
开源,英文名Open Source,即开放源代码,任何人可以在源代码的基础上进行学习与修改。它从58年前的黑客文化中缓缓演进,而最早催生这一文化的MIT技术模型铁路俱乐部的黑客们(Hackers),大都成为MIT AI实验室的核心成员。
如果说AI是一场饕餮盛宴,数据是原材料,算力是天然气,算法是菜谱,那么开源就犹如无数厨师经验与智慧合著成的一本永不完结的烹饪百科全书,其他厨师可以从中汲取经验来快速完成菜品,也可以指出书中的问题、贡献更多创意,让这本书经过无数人的完善后逐渐成为神作。
可以想象一下,一个人专门检查代码bug,它可能需要好几天的时间还有纰漏;而如果一群开发者和测试者来查bug,那么代码排错与演化的效率将得到惊人的提升。
如果能创建一个开放、有改进能力的环境,驱动成千上百的人才库去反馈并提供设计空间拓展、代码贡献、Bug定位以及其他的改进,而一个封闭项目中,要多么顶级的黑客才能仅依靠自己就做到与这成千上百人抗衡。
在开源文化中,黑客们追求的是更高质量的代码、更完善的项目,其动力也许是单纯的热爱,也许是对证明个人能力的渴望,但绝不是追求接近物质财富的东西。
与之相悖的是闭源,由专门的研究团队开发一个软件项目,不让别人知道源代码。选择闭源的机构无外乎几种目的,担心泄露机密,不想让竞争者使用它,或者想用它来卖钱。
这并不难理解,充斥着共享理念的开源文化,似乎与以营利为核心目标的商业世界天然不搭。即便是对在商业的考量中,开源的直接目的也不是为了营收,而是为了借此开拓市场和生态以获得更长远的收益。同时,开源也能有效防止闭源产品垄断市场的局面出现。
相较而言,传统开源项目会给开发者带来更大的压力,而开源开发者更为自由,他们只需专注在自己想要做的事情上,不必被上层的需求抽着鞭子往前走。
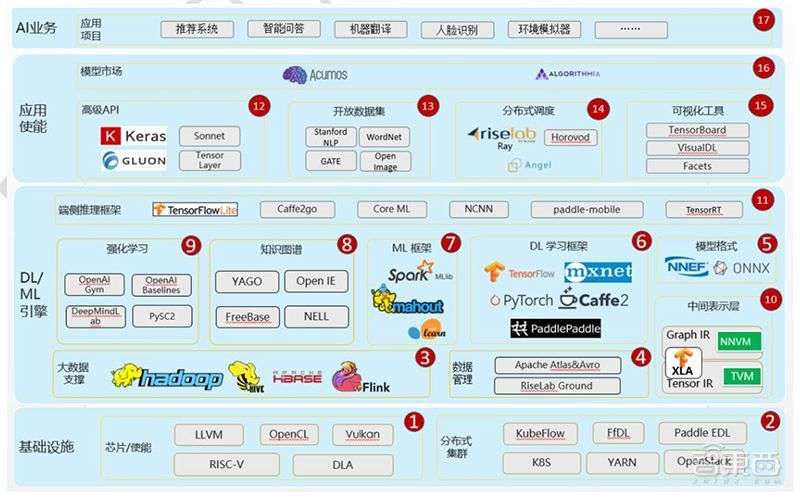
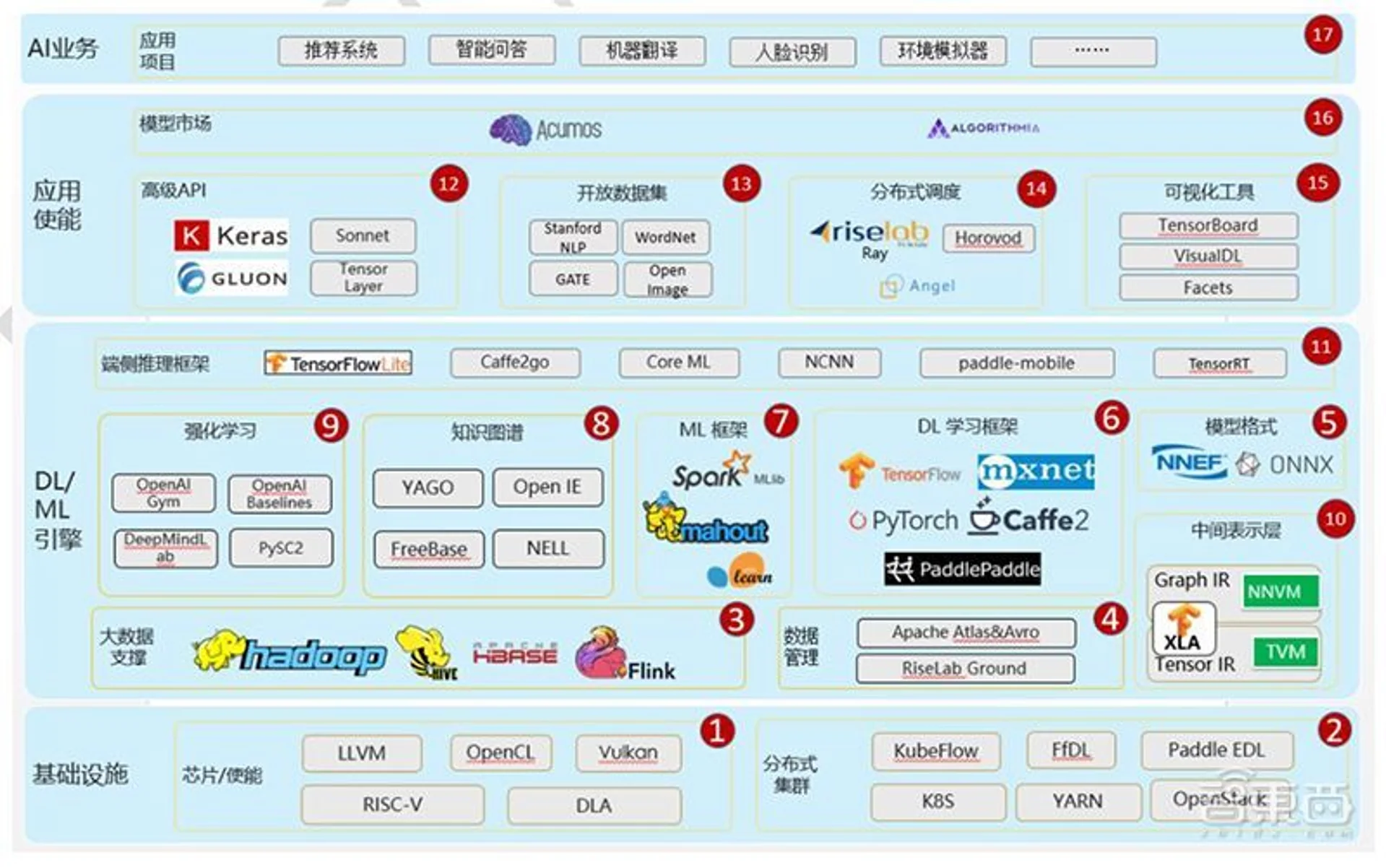
▲AI开源全栈示意图
微软就曾是闭源的典型代表,早期它采用软件授权的模式,为其商业软件建立起一整套完整定价。Windows操作系统正是微软典型的闭源商业力作之一。尽管开源之光Linux操作系统没能在商业战场上干过微软,但长期站在开源对立面的微软,最终还是选择了拥抱开源。
开源既然要开放代码,让成千上万人协作,那就需要一个足够友好和安全的开源托管服务,在这一背景下,GitHub应运而生。
2008年,克里斯·万斯克拉斯已从辛辛那提大学英语专业辍学了三年,同普雷斯顿一起经过夜以继日地合作写代码,终于打造出能提供优秀协作服务的代码托管平台GitHub,并专程找Twitter经典logo的设计者西蒙·奥克斯利设计出其吉祥物章鱼猫Octopuss。

▲克里斯·万斯克拉斯(左上),普雷斯顿(右上),Github吉祥物章鱼猫(图下)
经过十一年的发展,Github早已成为“全球最大程序员交友平台”,它每年发布的Octoverse年报已成为呈现这一年度热门开发项目、顶级编程语言等趋势的权威榜单。例如从Github上我们可以看到,近年数据科学、深度学习、自然语言处理、机器学习等主题的存储库正变得愈发流行,新的框架正吸引着成千上万的贡献者。
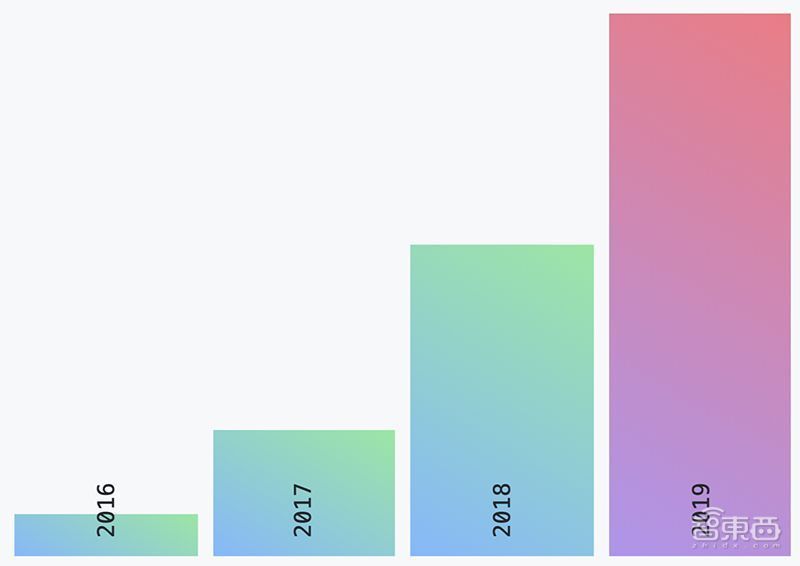
▲2016-2019年Github自然语言处理存储库的增长变化
大约也是从Github成立那年起,微软对开源文化的态度开始发生转变。
2009年,微软向Linux贡献2万行设备驱动代码;2011年,微软一度跻身Linux 3.0五大公司贡献者之一;2014年,“重塑”微软的CEO纳德拉喊出著名的“微软爱Linux”;2016年,微软推出了兼容 Linux 的 SQL 服务器数据库软件;2017年,微软成为GitHub上贡献代码最多的公司,这一宝座蝉联至今。
2018年6月,微软斥资75亿美元收购Github,全球轰动。
截至当时,GitHub上,聚集了约2800万开发者、高达8500万代码库,仅是在去年,70%的全球财富50强公司均使用Github为开源做出贡献,包括微软在AI时代的主要对手,苹果、谷歌、亚马逊等科技巨头。
02 群雄混战AI开源框架
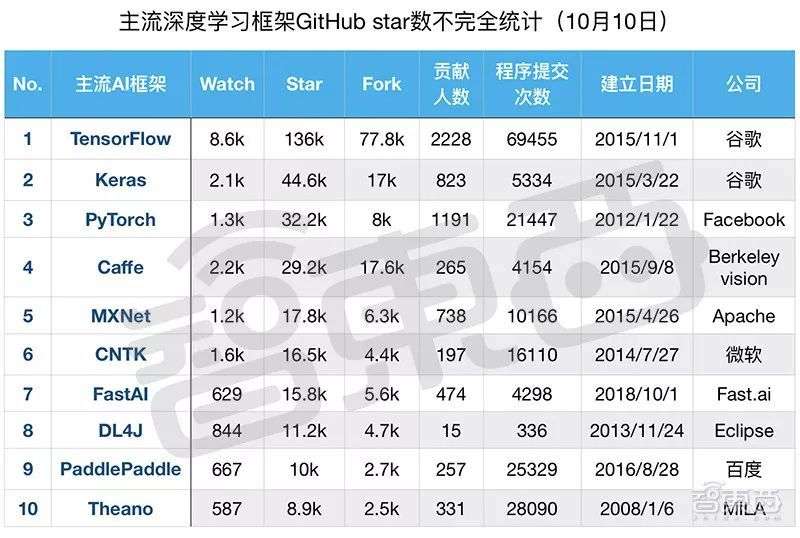
▲部分主流AI框架项目社区活跃度指标统计
AI框架上承应用、下接芯片,堪称智能时代的核心软件支柱。
11月7日,GitHub发布年度报告,贡献者最多的TOP10开源项目中,谷歌AI框架TensorFlow排名第五(9.9K)。
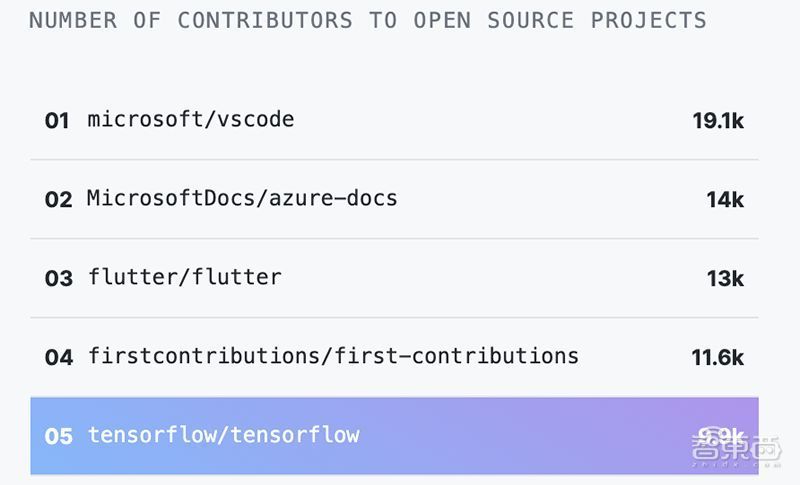
TensorFlow,当前AI开源框架的扛把子,承载了“业界开源典范”谷歌在AI时代的野心。
凭借一个开源手机操作系统“安卓”,谷歌占据全球80-90%的智能手机,坐拥超过40万的开发人员和十多亿用户,据说凭借广告、应用、授权及付费内容等收入,一年能给谷歌赚30亿美元。
“赢者通吃”的价值在安卓身上发挥的淋漓尽致,如今其在智能手机界的地位早已稳如泰山,令其他未入局的大公司屡屡扼腕。连微软创始人比尔·盖茨都公开表示,自己犯下最大的错误就是“因为管理不善,导致微软没有推出像安卓那样标准化的、非苹果的手机操作平台”。
2015年11月,谷歌第二代深度学习框架TensorFlow横空出世。
背靠谷歌这座开源大山,TensorFlow强势崛起,借助于英特尔、NVIDIA等硬件平台的配合打法,向全球开发者免费供给AI库与工具,成为Github上最受开发者欢迎的平台之一。
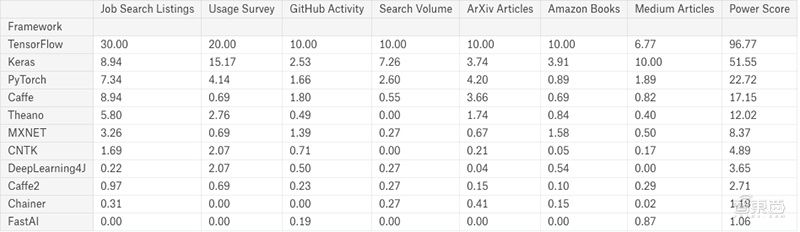
去年4.6万个项目依赖于这一平台,贡献人数从2238位直接贡献者增长到25166位社区贡献者。开发人数、贡献人数、受欢迎程度(star数)、谷歌搜索量都碾压其他一众开源AI框架。
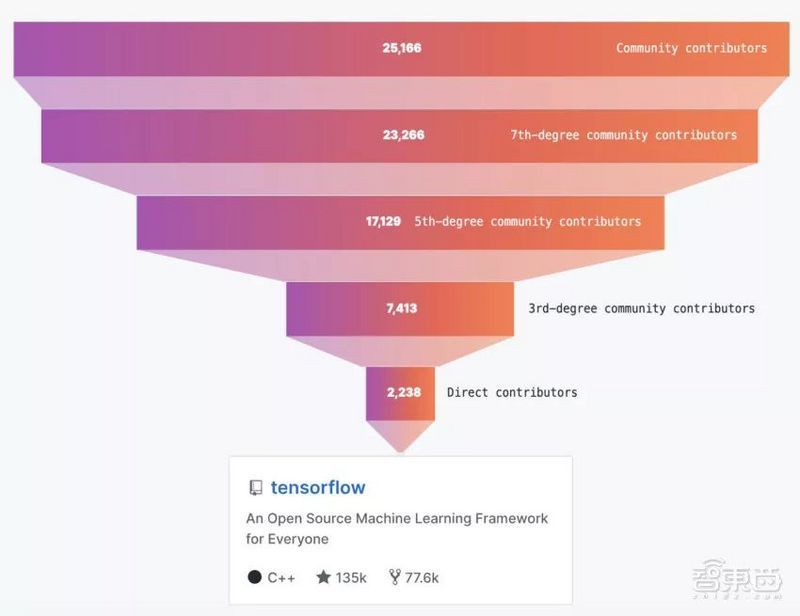
去年,国外数据科学研究者Jeff Hale调查了多个主流求职平台的AI相关在线职位搜索列表,其中TensorFlow的搜索量一骑绝尘。综合职位搜索、KDnuggets使用调查、Github活跃度、谷歌搜索量、ArXiv文章、亚马逊书籍、Medium文章等指标的评判,TensorFlow仍然遥遥领先。
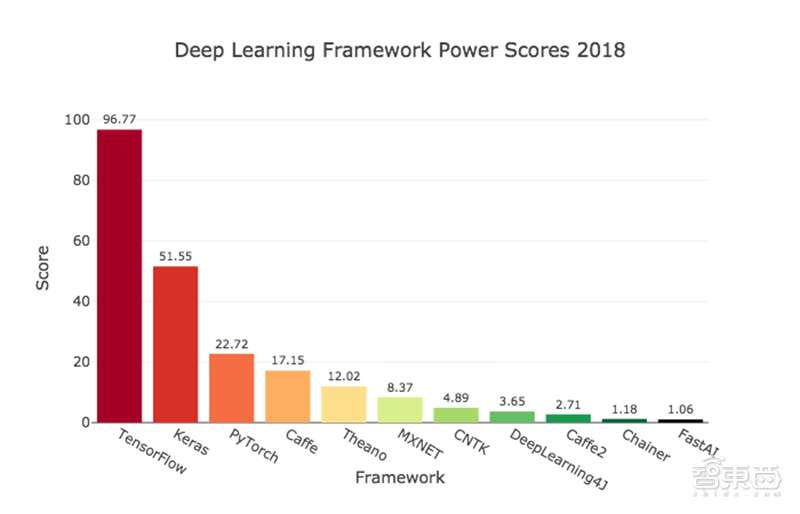
眼见AI接棒移动互联网高调归来,显然,其他科技巨头们不打算坐看谷歌独享AI开源的红利。
几乎在TensorFlow开源的同一时期,微软亚洲研究院开源机器学习工具包DMTK,通过Apache软件基金会免费向外界程序员提供System ML AI工具的源代码。
有些AI开源项目比TensorFlow更早出现。
比如,2015年1月,Facebook人工智能研究院(FAIR)就推出一组基于Torch机器学习框架的开源深度学习工具。同年4月,亚马逊推出机器学习托管服务Amazon Machine Learning,允许任何开发者轻松使用历史数据开发并部署预测模型。
不过这些项目尚不足为惧,在TensorFlow开源一年又两个月后,它最大的宿敌终于现身。
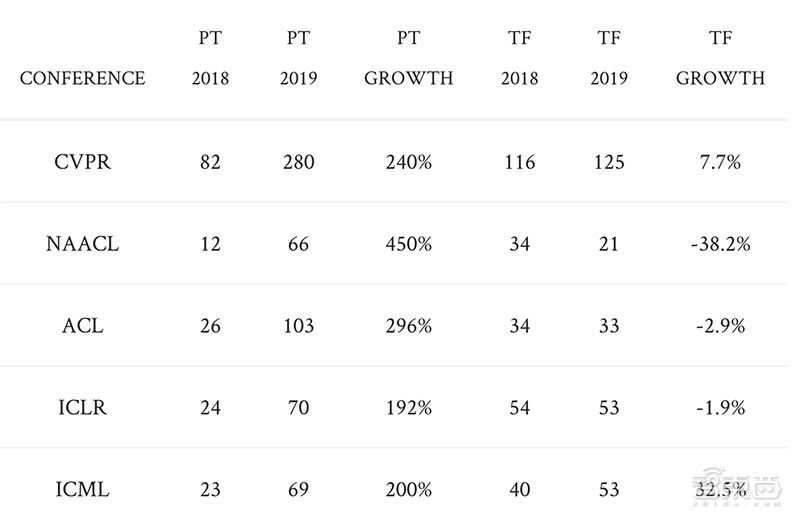
2017年1月,Facebook推出机器学习框架PyTorch。近两年来,PyTorch持续大举收割AI学术开发者,并且今年在视觉、语言、通用机器学习等多个顶会的论文流行度碾压TensorFlow,成为AI学术界新的王者。
许多研究人员表示,相比TensorFlow,PyTorch的集成方式、API都设计的更好,而且业界有传闻说PyTorch的速度要比TensorFlow更快。甚至相传谷歌内部许多人员也希望使用TensorFlow意外的框架,这意味着谷歌早早铺路的AI生态建设并不如安卓那般一帆风顺,相反危机四伏。
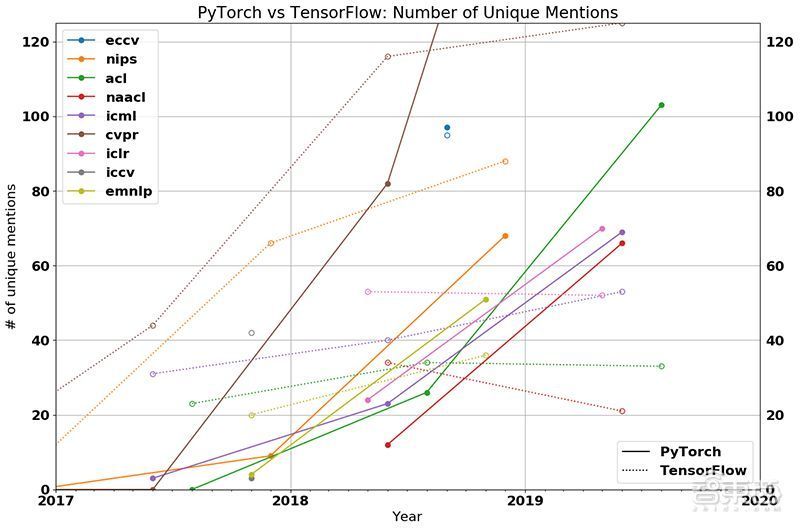
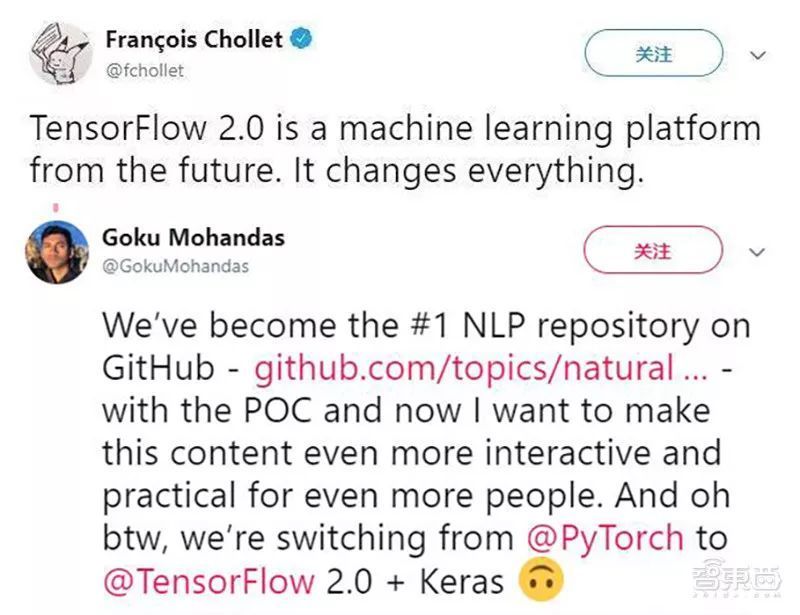
TF与PY之争也成为AI领域热议的话题。有趣的是,去年谷歌Facebook接连发布TensorFlow和PyTorch新版本。
前者有谷歌深度学习科学家、Keras作者Franois称赞为来自未来的机器学习平台,苹果公司AI研究员Goku Mohandas说他们正从PyTorch转向TensorFlow 2.0+Keras。后者则获得图灵奖得主、深度学习鼻祖之一Yann LeCun的转发支持。
曾因开源问题引发争议的微软和亚马逊,近几年也走在AI开源的路上。
亚马逊对出身学界的MXNet框架情有独钟。2016年11月宣布将其作为官方深度学习平台,用于亚马逊AWS,并于今年1月决定开源其机器学习服务平台SageMaker Neo。微软则在2017年开源了其内部深度学习框架CNTK的2.0版本,重命名为微软认知工具包(Microsoft Cogntive Toolkit)。
面对拥有庞大独立AI生态的谷歌,微软、Facebook、亚马逊等巨头选择联合。2017年9月,他们发起深度学习开源联盟ONNX,旨在提高各种AI工具间的通用性。阿里、腾讯、百度、华为、小米等国内科技公司以及英特尔、NVIDIA、高通、AMD、Arm、IBM、惠普等芯片及服务器巨头纷纷加入其中。

去年智东西采访微软项目总经理Venky Veeraraghavan时,他曾表示微软已和谷歌做了充分沟通,但当时谷歌决定暂时不会积极参与到ONNX的工作中。
而截至目前,谷歌仍未公开表现出加入这一阵营的意向。
03 大神云集,AI开源中的华人之光
MXNet、TensorFlow、PyTorch等世界一流的开源AI框架背后,都有着不容忽视的中国身影。
亚马逊所青睐的MXNet由DMLC(Distributed/Deep Machine Learning Community)打造,其核心成员均为中国人。
MXNet源起三个不同的开源项目,一是在美国的陈天奇、在加拿大的许冰和在香港的王乃岩牵头的CXXNet,二是上海张铮及其学生牵头的Minerva,三是在新加坡的李沐牵头的purine2。

▲陈天奇
在2014年NIPS上,同为上海交大校友的陈天奇和李沐经过交流,发现大家普遍在做重复性工作,于是决定合作开发MXNet。随后,越来越多的开源贡献者参与到MXNet的开发和维护工作中。在亚马逊将MXNet定为官方框架前,图森、地平线、Wolfram等公司都为MXNet贡献了很多代码。
清华大学毕业生贾扬清在加州大学伯克利分校攻读计算机科学博士期间,创立了对移动端友好的开源深度学习框架Caffe,被微软、雅虎、NVIDIA、Adobe等公司看好并采用。毕业后他到谷歌任科学家,同Jeff Dean等大神参与TensorFlow的开发,然后又在2016年跳槽去了Facebook,并主导了Caffe2移动端深度学习框架和ONNX项目的开发。

▲贾扬清
因为传统PyTorch偏研究,Caffe2偏应用实践,两个框架之间存在很难跨越的鸿沟,一年半前,Facebook决定将这两套框架合并成PyTorch 1.0,实现从研究开发到生产实践的无缝对接。

如今,陈天奇已加入美国机器学习创企OctoML任CTO,明年秋季将加入卡内基·梅隆大学任助理教授。李沐现任亚马逊AI主任科学家。贾扬清则于今年3月作别Facebook,加盟阿里巴巴任副总裁、阿里云智能计算平台事业部总裁,并担任阿里巴巴开源技术委员会负责人。

04 BAT入场,中国开源AI起步中
国外开源AI框架的厮杀正紧,国内AI企业在AI开源项目上的格局则相对更为分明。
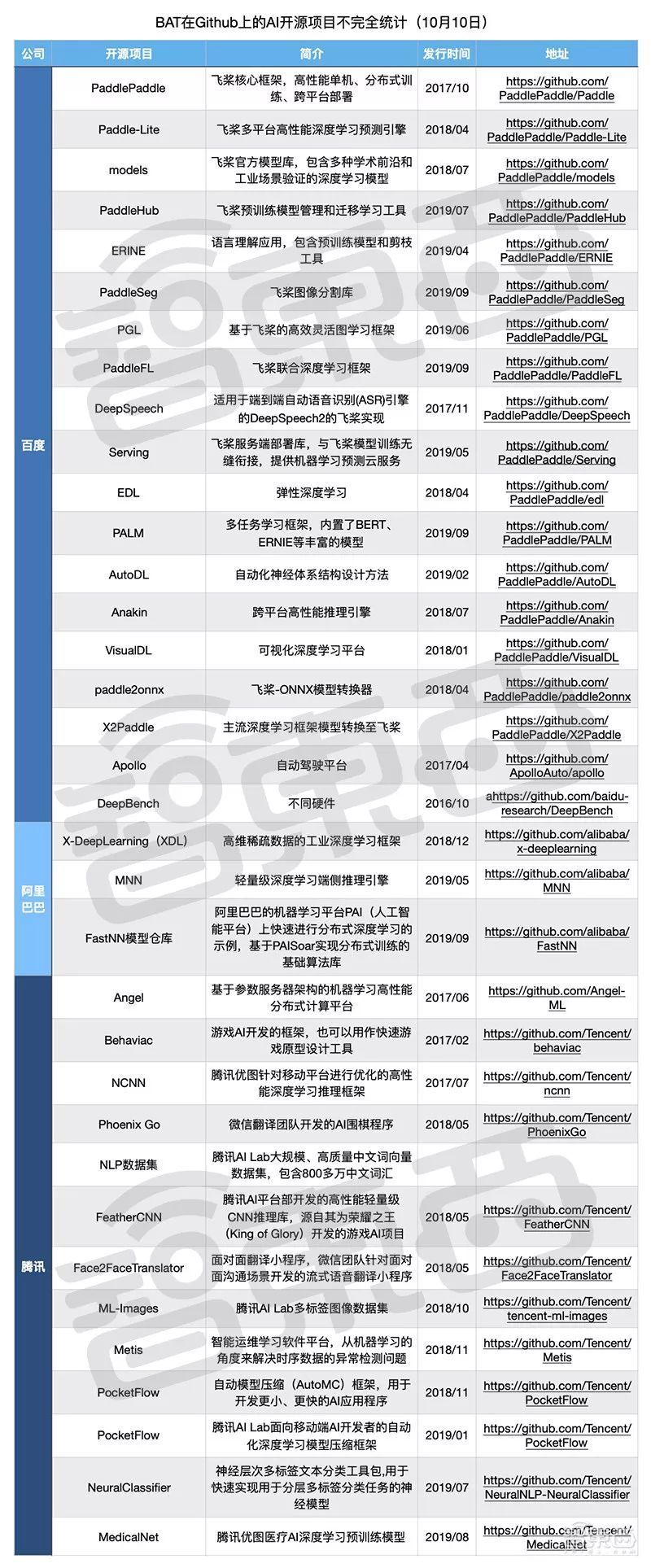
▲BAT在Github上的AI开源项目不完全统计
目前唯一跻身Github全球最受欢迎AI框架排行榜,能与TensorFlow、PyTorch等相提并论的是百度飞桨。
百度飞桨源自于百度深度学习实验室于2013年创建的内部工具“Paddle”,2016年9月正式宣布开源。这使得百度成为继谷歌、Facebook、IBM后第四家将AI技术开源的公司,同时也是打造国内第一个且唯一中文开源深度学习平台的公司。
飞桨根据本土化特点将开源框架与应用层面做了更好的结合,比许多现有深度学习框架更快、更好用。贾扬清曾评价它在简洁、灵活、快速等领域功力不俗,且解决了Caffe早期存在的一些遗留问题。
今年8月,百度还对外发布了面向终端和边缘设备的端侧推理引擎Paddle Lite Beta版,不仅支持飞桨,还支持TensorFlow、PyTorch和ONNX模型格式。
很有意思的是,2016年7月9日,美国NASA在Github上公开了47年前登陆月球的Apollo 11源代码。
恰好一年后,百度宣布开源其自动驾驶系统Apollo,其自动驾驶软件可供任何人免费下载及修改使用。
目前飞桨在Github上的star数达1.02万,fork数达2700,有264位贡献者,提交超过2.5万commits。而Apollo比飞桨还要受欢迎,star数达到1.53万,fork数超5200。

腾讯也大约从2016年起不断将内部开源出来的优质项目发布在Github上,如今它在Github全球公司贡献榜上位居前十。
截至今年8月,腾讯已在Github上发布82个开源项目,其中包括7个方向的AI开源项目。
Angel是腾讯第一个AI开源项目,最新3.0版本升级为全栈机器学习平台,擅长稀疏数据高维模型的训练,可支持多类图计算算法,覆盖了机器学习全流程。它可以与TensorFlow、Caffe等业界主流深度学习框架很好地兼容。
Angel早在2016年年初就在腾讯内部上线,应用在微信支付、QQ、腾讯视频、腾讯社交广告、用户画像挖掘等业务中,2017年6月在Github上低调开源。
当前Angel平台包含超过50万行代码量,其star数已经超过5400,fork数达1400,总计有40位贡献者,提交2300多次commits。
除了Angel之外,腾讯还开源了面向手机端的跨平台高性能神经网络前向计算框架NCNN、首个医疗AI深度学习预训练模型MedicalNet、AI围棋程序Phoenix Go、包含800多万中文词汇的高质量中文词向量NLP数据集、业内最大规模的多标签图像数据集ML-Images、全球首款自动化深度学习模型压缩框架PocketFlow。
阿里巴巴在Github上主体账号的总项目数是国内最多的,据贾扬清介绍,在AI和大数据领域,阿里已经贡献超过100万行的代码,深度参与超过10个开源项目。
贾扬清在今年9月的阿里云栖大会上说,阿里的AI与开源、开放的生态是分不开的,会通过开源与云平台的合作,推进开发者生态建设,在拥抱开源的同时贡献开源。
单从近一年来看,阿里在AI领域先后开源面向高维稀疏数据场景的深度学习框架XDL、轻量级深度神经网络推理引擎MNN、基于PAISoar的分布式神经网络仓库PAI-FastNN。
而随着阿里云与Facebook宣布在AI开源项目上展开合作,双方计划开源、共享、合作开发框架、AI模型、文件等,将成果以 PyTorch 的形式共享到 GitHub,阿里云机器学习平台将能支持PyTorch框架。这会进一步降低AI开发和应用门槛,同时推动PyTorch框架在产业界的普及。
另外,阿里也通过携手Facebook,拟将PyTorch项目文献、教程等资料更快、更准地翻译成中文版本,让国内开发者能第一时间学到最新PyTorch。

商汤和港中大看起来也是PyTorch拥护者,开源的最大目标跟踪库PySOT、物体检测工具包MMDetection、时空图卷积网络(ST-GCN)骨架动作识别MMSkeleton均基于PyTorch。
就现在来看,国内自主研发开源深度学习框架的企业还属于“稀缺物种”。
目前有苗头成为新成员的是华为和旷视,华为预告将在明年第一季度开源其全场景AI计算框架MindSpore,旷视的深度学习框架Brain++也已经在计划开源,此前旷视研究院的原创ShuffleNet Series算法已经开源在Github上。
05 产学研合力加速中国AI开源进程
除了开源AI项目之外,国内外公司也在积极参与AI开源社区建设。
比如,百度、腾讯、华为、中兴、AT&T等国内外知名企业均加入了LF深度学习基金会,共同打造中立开源社区。
目前广泛存在的专利许可费高昂、专业人才有限等问题,均可在AI开源社区的帮助下有效改善。另外,开源还会帮助数据科学家、工程更高效地做大规模系统性测试、性能调优、实际落地等工作,带给他们更好的用户体验。
在扶持开发者和创企的同时,开源社区也从其模式中构建了庞大的反馈循环。开发者及团队带给社区建设者的反馈,是解决问题中的想法、改进平台的建议、更多的数据、更成熟或更创新的模型和算法、甚至更多的用户,这些反馈会反过来推动开源社区主导者对技术的理解和业务的优化,为后续的数据采集及技术分析铺路。
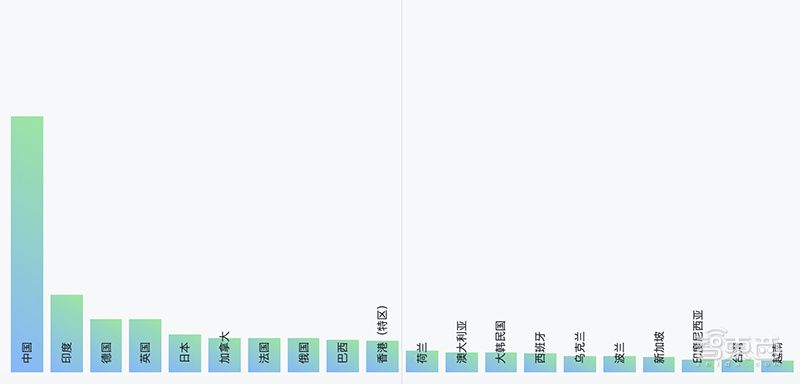
根据最新发布的Github年度报告,我国在开放源代码的使用量上遥遥领先,开发者fork和clone的项目比去年多了48%。
过去一年,亚洲开发者社区在2019年增长迅速,约36%的私人存储库创建自中国、印度、日本等亚洲开发者。
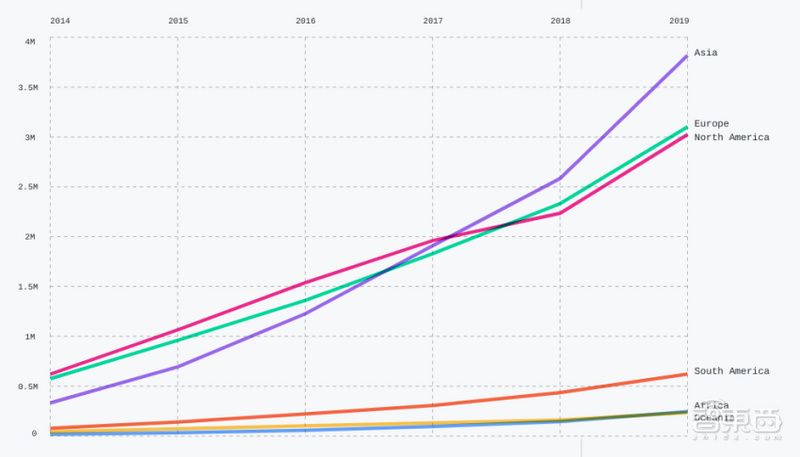
▲自2014年以来,Github上亚洲的贡献者群体的年增长率已超过欧洲和北美的贡献者群体
考虑到国内AI开源发展现状距离国际最领先水平还有距离,政产学研的力量正更为紧密的集结在一起。
今年3月,新一代人工智能产业技术创新战略联盟(AITISA)组织下,新一代人工智能开源开放平台OpenI启智发布,目前启智平台开源的项目有七个,包括集成百度飞桨核心功能的启智VisualDL、开源AI处理器项目OpenI海藻等。
鹏城实验室、北京智源人工智能研究院、清华大学、北京大学、国防科技大学、北京航空航天大学、浙江大学、华为、百度、阿里、腾讯、网易、小米、平安、京东、字节跳动、科大讯飞、旷视、商汤、滴滴、中科类脑等单位均参与这一开源开放平台。
此外,今年4月,国家人工智能标准化总体组发布《人工智能开源与标准化研究报告》,华为、腾讯、京东、浪潮、英特尔、IBM、商汤、云从、云天励飞、华夏芯等公司均参与了编写工作,对AI开源现状及相关生态进行了描述和分析。

随着AI开源项目的蓬勃发展,这种共享文化正激励着更多不同行业的公司尝试AI,创建符合其自身业务需求的平台。
借助开源,他们无需在尚未构建且无法自定义的AI软件上花费数百万美元。他们本身拥有海量的行业数据,只需招揽少量的AI开发者,即可在开源AI平台及模型的帮助下更高效、低成本的完成智能化任务。
根据Scopus的数据,从2007至2017年,中国发表的AI相关论文数量从5995增至15199篇。
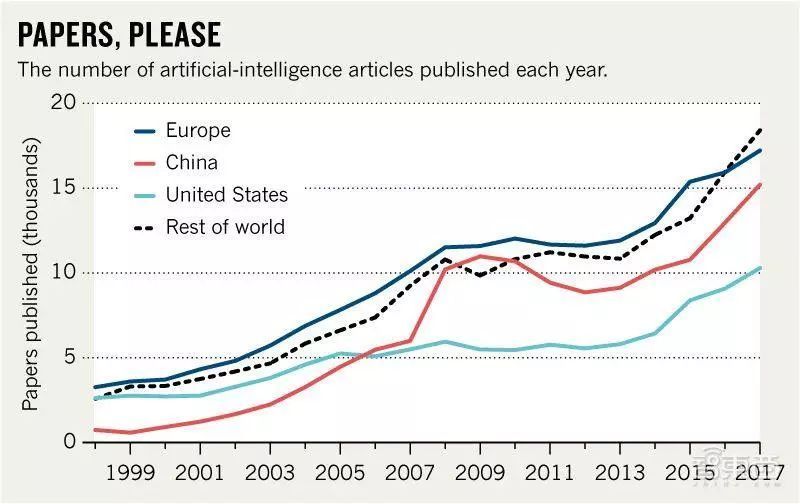
许多企业在构建AI解决方案时,都会大量用到开源的算法。在开源的推动下,AI创业公司如雨后春笋般涌现。报告显示,中国AI企业数量达到745家,仅次于排名第一的美国。其中,2018年发生融资事件的企业有577家,融资总额达3832.22亿元,排名全球第一。
06 中国AI开源面临的困境
尽管我国的AI事业看起来蒸蒸日上,但短板一直还存在。在基础层建设、创企困局、安全漏洞、道德难题等方面,AI开源还有很多值得探讨的空间。
而政产学研的力量正集结在一起,试图建立一个更加稳健强大的中国AI生态系统。
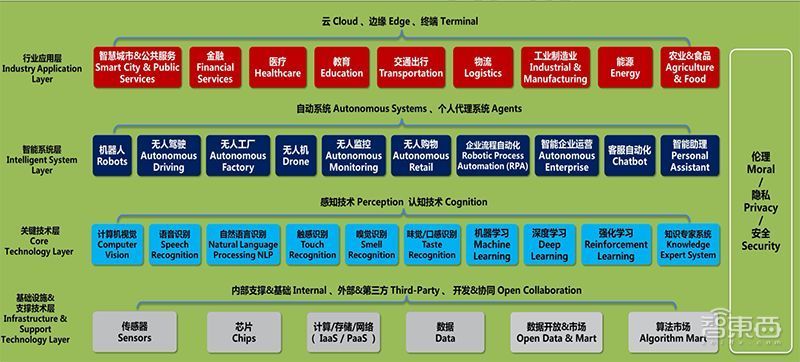
▲人工智能产业生态圈全景图
1、应用层强,基础层弱
根据科技部发布的《中国新一代人工智能发展报告2019》,中国是AI专利布局最多的国家,在技术层呈现中美双寡头竞争格局,在应用层中国专利领先。
但在AI基础技术及工具的研发方面,我国仍然相对落后,AI基础技术的核心力量都掌握在美国的手中。
AI开源项目一方面能推动AI技术更快落地到具体业务和应用中,但也可能致使更少的开发者愿意去从事难度大、成效未知的基础性研发工作。而随着我国高校AI教育体系的逐步完善,对研究项目方向的设置、对学生的引导将起到关键作用。
2、开源基础设施环节薄弱
就目前来看,我国唯一在国际上拿得出手的AI框架只有百度飞桨。而飞桨的受欢迎程度尚不足以排进全球AI框架前十名。
即便是在国内的企业和高校中,TensorFlow、PyTorch等美国公司研发的开源框架更受开发者的青睐。而更令人担忧的是,开发者最热衷于上传代码的Github平台同样在美国公司手中。
诚然,绝大多数程序员都崇尚公平、开放的开源共享文化,但此前已经有各种例证显示了政治和狭隘观念可能造成的负面影响。
比如上周全球第二大开源代码托管平台GitLab公然发文,称考虑“当前地缘环境”,拒收中、俄公民,并且禁止现员工前往这两个国家。
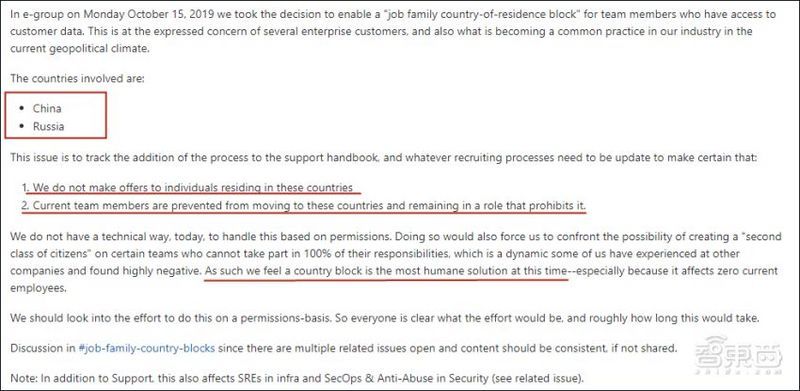
如果美国执意要竖起“数字铁幕”,那么我国建立完全独立自主的开源基础设施已成当务之急。
3、小公司做AI开源不占优势
无论国内还是国外,AI开源更像是巨头的专场。亚马逊、谷歌、BAT等公司,除了本身技术实力过硬外,可直接豪掷千金买技术、团队、人才,建设一套更为完整的开源体系。
但对于刚刚起步的小公司而言,资金、技术、人才等压力往往使得他们在通往开源的路上更为束手束脚。比如美国公司Mycroft开源的语音平台需要支持几十种语言,它不得不与Mozilla以及更大的开源社区合作进行一些国际化工作,但这些需要耗费很多时间。
少数技术实力雄厚的初创企业搭建了自己的深度学习框架。但现实中,人们更容易倾向于信赖已经得到大众认可的事物,即便创企能提供更高性价比的产品及服务,一些客户出于安全等考量仍会更信任抢先培养了用户习惯的软件产品。
即便是国内大公司都要思考如何吸引更多开发者选择自己的AI框架,小公司面临的阻碍往往更多。
4、安全漏洞防范与标准规范
和信息技术相关的所有软硬件一样,开源AI框架也存在技术漏洞、人为缺陷等造成的安全风险。
开源社区通过不断监控软件代码中的缺陷和漏洞,提供额外的安全性,这对像AI这样的新兴技术尤为有益,但仍不可避免会存在一些潜在的威胁。
去年,谷歌TensorFlow曾爆出重大安全漏洞,虽未造成实质影响,却引发业界担忧。当时有专家评估,类似的漏洞可能摧毁所有基于该平台开发出的AI模型,而这些模型可能大量涉及安防、识别、城市交通、公共服务等事关社会民生的关键应用。
这也给我们敲响警钟,在建设开源AI框架过程中,必须严格防范可能的安全漏洞问题,同时逐步构建完善的安全要求与测评评估标准工作。
5、数据隐私保护与技术滥用
AI开源项目被用地不得当,可能引发道德上的灾难。关于数据隐私保护引发的争议已经屡见不鲜,除此之外,近期技术滥用问题一度引起轩然大波。
就拿今年AI换脸开源项目DeepFake来说,已经有一些人利用这一技术去从事一些灰产,甚至对许多无辜群体造成人身攻击和心理伤害。智东西曾对国内AI换脸产业做深入调查(AI换脸黑产:100元打包200部换脸情色片,5张照片就可定制视频)。
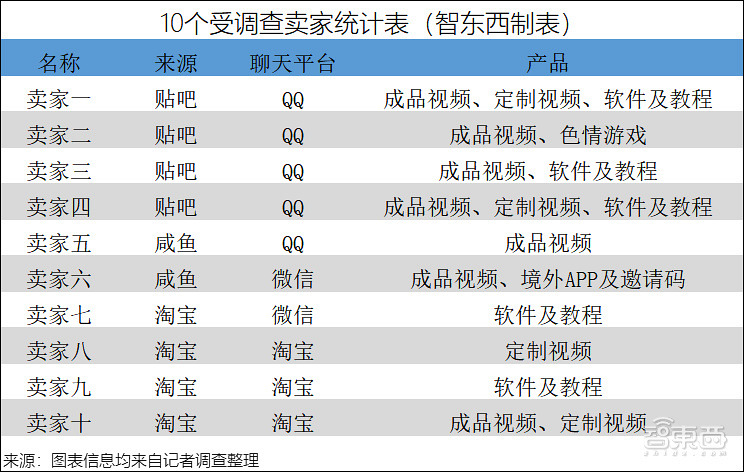
▲被调查的10个卖家资料整理
今年AI技术与道德审查的法规制定也成为全球多个AI会议探讨的核心话题之一。
另外由于AI开源项目降低了AI落地的门槛,一定程度上也导致市场上现有的AI产品良莠不齐。比如一些做智能门禁的企业直接借用开源平台中的模型,没有结合实际数据做进一步的优化,投入实际应用后,对人们的生命财产安全也会造成一定风险。
结语:国内AI开源建设需要更多开发者支持
上层软件走向开源开放是大势所趋,封闭知识产权会逐渐融入到开源基础架构之中。
AI于开源而言,或许与其他软件别无二致。而开源于AI而言,却是促进AI应用创新与更多行业智能化普及的重要驱动力。从当下AI在各国的战略地位来看,开源AI框架有望成为像云API那样成为主宰AI市场的核心引擎。
近年随着AI算法的持续丰富,开源与科研、工程的结合也越来越紧密。开发者所关注的开源AI核心要素,也从更高的性能转为如何能让算法在应用中更快更好的落地。而更快速、更好用的AI框架,以及与各种硬件更加优化的协同,都有望为AI发展注入新的活力。
当前我国在AI应用层基本站稳脚跟,在数据资源、数理人才、市场环境等方面均有很大优势,再加上战略引领、政策支持助力,AI开源开放平台、完整AI生态链的相关建设正在持续推动中。这或许会是一个长期的工作,不仅需要产学研各类机构的协同努力,也需要更多开发者的鼓励与支持。


