谷歌AI也会被难倒 百年老图到底是鸭是兔?


鸭子还是兔子?
文章来源:量子位
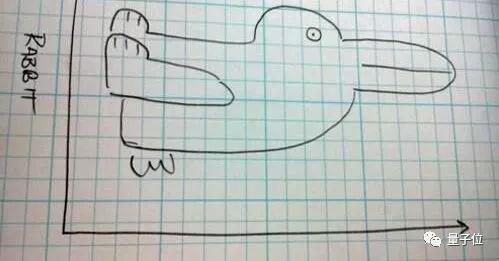
上面这张图,画的是鸭子还是兔子?
自从1892年首次出现在一本德国杂志上之后,这张图就一直持续引发争议。有些人只能看到一只兔子,有些人只能看到一只鸭子,有些人两个都能看出来。
心理学家用这张图证明了一件事,视觉感知不仅仅是人们看到了什么,也是一种心理活动。但是,这张图到底应该是什么?
上周四,有位学者决定让没有心理活动的第三方看一下。然后就把这张图片给了谷歌AI,结果AI认为78%的概率是一只鸟,68%的概率是一只鸭子。

所以,百年争论可以歇了?鸭子派胜出?
不不不,新的争论刚刚开始。
这下难倒了谷歌AI
上面那个结论刚出,就有人跳出来“抬杠”。
只要把这张图竖起来给AI看,它认为是一只兔子,压根就没有鸭子的事儿。

咦?谷歌AI反水了?
为了搞清楚这件事,供职于BuzzFeed的数据科学家Max Woolf设计了一个更复杂的实验,他干脆让这张图旋转起来,倒是要看看,谷歌AI什么表现。
就是这么一转,成了推特上的热门。
咱们以鸭子嘴(兔子耳朵)为参考,说下这个实验的结果。过程如下所示。红色代表兔子,蓝色代表鸭子。
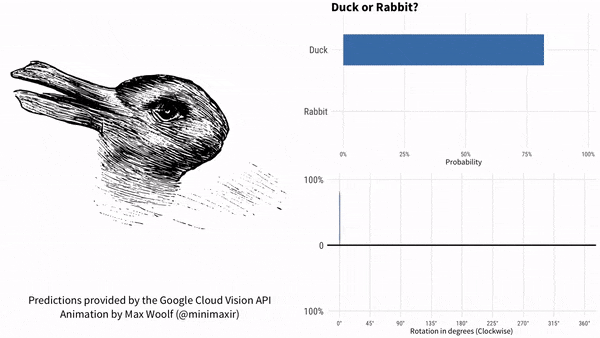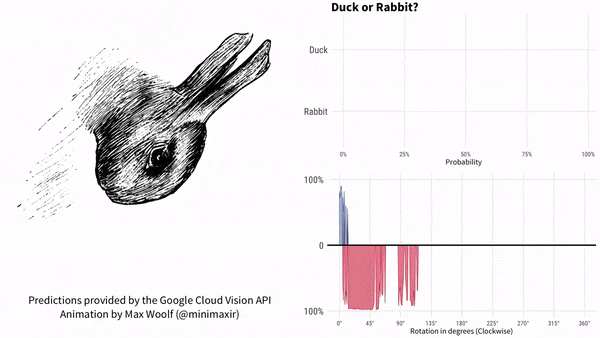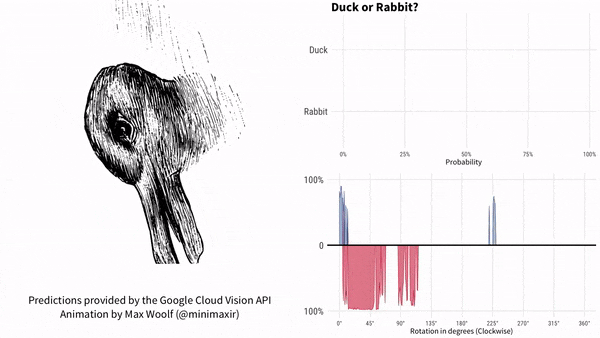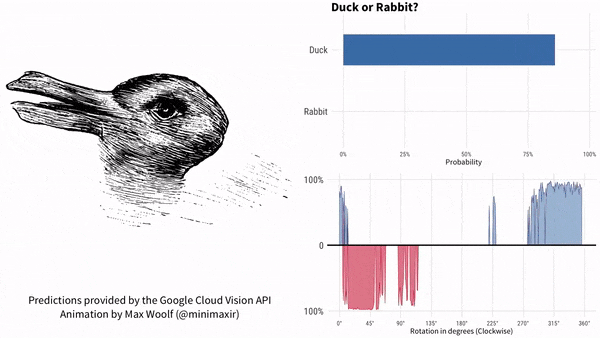
图片顺时针旋转。谷歌AI最初认为是鸭子,鸭子嘴指向9点方向。随着鸭子嘴向上转到10点方向,很快谷歌AI就认为画里面是兔子了,直到鸭子嘴转到2点方向之后。此后一段时间,谷歌AI认为既不是鸭子也不是兔子。一直到7点方向,谷歌AI再次肯定是一只鸭子。
有人说此刻谷歌AI的内心,可能就像迪士尼动画兔八哥里的这个场景。

还有人给了更多类似的挑战图片,想考验一下谷歌AI的水平。
比如这种:
以及这种:

等等等等……据说能看出来鸭子,又能看出来兔子,说明一个人的想象力更好。
大家如果有兴趣,可以自己去尝试。
这里用到的谷歌AI,实际上是谷歌的Cloud Vision。这个服务提供了预训练的机器学习模型,可以用来理解图片内容。地址在此:
https://cloud.google.com/vision/
页面上提供了Try the API,直接传图就行~
鸭兔幻觉
“鸭兔同图”问题让不少网友犯了难,这是一个比“鸡兔同笼”更玄幻更有意思的问题。还有一大波人类,正常尝试判断AI的心理状态……
网友sangnoir认为,纠结图中到底是什么完全没有意义,图像本身中既包含了兔子又包含了鸭子,人类尚且觉得两者都在,何必非得让AI去做“二选一”的定性呢?
下面这个数字大家都认识,但是旋转起来,到底是几呢?

△ 若旋转起来,图片是“6”还是“9”?
谈到旋转,更进一步,之前有个“旋转舞者”的问题更困难,下面这个小人到底是顺时针还是逆时针旋转,人类的看法也兵分两路↓↓↓

实际上,当你视线以从左往右的方向扫过这张图时,你看到的是逆时针转圈,反之,当你先看到的是右边时,你眼中的她是顺时针的。在计算机视觉上,还有一个专门的名词解释这个现象,即多稳态/双稳态感知。
也有网友表示,这件事恰恰反映了AI识别物体的能力已经高于人类了。
他认为,之所以Google Cloud Vision会连续给出不同答案,是因为AI系统每隔一段时间就会基于旋转的图像重新判断并实时更新。
而人类的大脑往往就卡在第一印象了,所以才会咬定一个物种不放松。
也有人表示,这件事也启发了视觉从业者反思AI识别物体时的方向问题。
比如网友Sharlin就认为,人类在判断物体时对于空间的认识具有先验性,用这样的标注数据训练出的模型,在不知不觉中也将空间和方向等因素考虑在内了。
但是,现在大多数视觉算法都想努力实现某种程度的旋转不变性,还提出了“尺度不变特征转化(SIFT)”等概念。“不变性”可能也反映了人类的局限性,输入方向也是一个重要考虑因素。
胶囊网络或许可行
同一张图片,由于位置不同,AI就产生了不同的判断。也有很多人想到了更多。
传统的卷积神经网络CNN架构中有个弊端,就是缺乏可用的空间信息。
一般来说,CNN提取、学习图像特征来识别物体。拿面部识别任务来说,底层网络学习一般性特征(比如面部轮廓等),随着层数的加深,提取的特征就越复杂,特征也精细到眼睛、鼻子等器官。
问题来了,神经网络用它学习到的所有特征作出最后的输出,但唯独没有考虑到可用的空间信息。人类可以识别出下面这张有些错位的人脸,但CNN就不能。

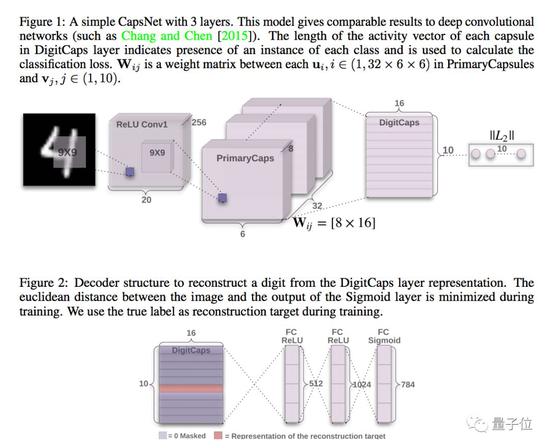
其实,让神经网络自己学会判断空间的研究已经有了。2017年,“深度学习”三巨头之一的AI大牛Geoffrey Hitton就提出了一种“胶囊网络”(Capsule Networks)的概念。
胶囊网络的解决办法是,实现对空间信息进行编码,也就是计算物体的存在概率。这可以用向量来表示,向量的模代表特征存在的概率,向量方向表示特征姿态信息。
在论文Dynamic Routing Between Capsules中,Hinton和谷歌大脑的同事Sara Sabour、Nicholas Frosst详细解释了“胶囊网络”的详细情况。
Hinton等人表示,人类视觉系统中,有一个“注视点”的概念,能让人类在视野范围内只对极小部分的图像进行高分辨率处理。

这篇论文假设一个注视点带给我们的信息不仅仅是一个识别对象及其属性,还假设我们的多层视觉系统在每个注视点上都创建了一个类似分析树的东西,并忽略这些分析树在多个注视点之间如何协调。
分析树通常靠动态分配内存来构建,但是这篇论文假设对于单个注视点来说,分析树是从固定多层神经网络中“雕刻”出来的,就像用石头刻出雕像一样。
神经网络的每一层会被分成很多组神经元,每一组称为一个capsule,而分析树的每个节点对应着一个活跃的“胶囊”。
胶囊是输出是一个向量,这篇论文中,在保持它方向不变的情况下应用非线性缩小了它的量级,确保这个非线性输出不大于1。
也正因为胶囊的输出是一个向量,确保了能使用强大的动态路由机制,来确保这个输出能够发送到上层合适的parent处。
胶囊网络现在的研究阶段,就像本世纪初将RNN应用于语音识别的阶段。有非常具有代表性的理由相信这是一个更好的方法,但很多细节还需要接续观察。
想看“胶囊网络”的具体信息,请戳量子位此前报道:
大神Hinton的Capsule论文终于公开,神经网络迎来新探索
— 完 —
订阅AI内参,获取AI行业资讯

购买AI书籍
