自生长自适应,知识系统的社交网络实践

当创作的权利归于每一个人,当内容的分发触达越来越便捷,我们在生活中所碰到的最大问题就成了因信息过载而带来的有效信息、有效关系获取困难。如何从令人眼花缭乱的信息流中快速获取到有价值的信息、对味的人,便成了当下新的问题。
试图让无序的信息世界变得有序,这个解法便是知识图谱。
什么是知识图谱?
知识图谱是由Google公司在2012年提出的概念,其学术定义为:“知识图谱指语义网络(Semantic Network)的知识库”。用白话来说,知识图谱就是一张呈现了各种实体(概念)自身属性与彼此间关系的网状图。不同于我们常见的树状结构或表状结构,网状结构能够基于边的连接,串联起不同实体,从而形成更立体的结构、支撑起更高的复杂度。
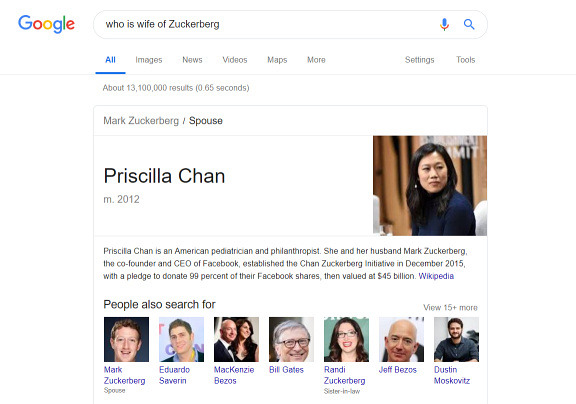
高价值的知识图谱,具有非常广泛的应用场景。以知识图谱在搜索场景中的应用为例,在Google中搜索“who is wife of Zuckerberg”,我们能够看到展示在页面第一位的就是一条结构化的结果。知识图谱的应用使得搜索引擎不仅能够检索原始网页,更能够基于原始的网页信息,更快速直白的给出答案。
知识图谱的价值并不止步于此。只要在涉及到认知智能(涉及知识推理、因果分析等)的场景里,知识图谱都能够有不同程度的应用。以反欺诈领域为例,一个典型案例就是国内的天眼查,通过开放的企业注册信息、投融资新闻,天眼查串联起了不同人物、不同公司间的投融资和控制关系,让我们能够通过一个单点就挖掘出系列的组合信息。
如何构建出一张有效用的知识图谱?
为了更迅速地构建出有效用的知识图谱,业界做了很多尝试。
首先,是信息的抽取。对于垂直领域的知识图谱而言,其基础数据可以来源于业务自身的数据,也可以来自网络中的公开数据的爬取。前者以数据库表的方式私密存储,相对结构化;后者则公开于网络上,非结构化,需要抓取和再处理才能投入使用。对于非结构的数据,往往依赖自然语言处理技术,先从非结构化的自然语言中抽取出结构化的信息组合,会涉及诸多技术点:命名实体识别(Entity Recognition)、关系抽取(Relation Extraction)、实体统一(Entity Resolution)、指代消解(Coreference Resolution)等。如下图,就给出了自然语言进行实体和词性拆解的一个示例。

其次,是信息的存储。在完成基础的信息抽取后,就需要将节点、关系更好的存储起来以便于后续的查询应用。最主流的就是以RDF(Resource Description Framework)的方式进行存储,其本质是描述了一个数据模型以统一的标准,来描述实体/资源与彼此间的关系。
最后,是知识图谱的应用。知识图谱本身作为一种信息的再组织,还是需要找到合适的业务应用场景才能够发挥效应。除了传统的数据分析和规则关系查询外,在引入概率统计的方法后,知识图谱的应用表现出新的可能性。比如,将聚类方式应用于知识图谱,算法首先计算了不同节点间的距离关系,再基于距离关系归纳出不同的节点组和组内密度,从而形成了自适应的规则。以反欺诈的应用场景为例,不同用户的工作岗位、年龄、收入情况可以抽离出不同的族群,更容易评估不同族群的风险程度。概率统计方式的引入,大幅降低了知识图谱对于人为规则定义先验需求的依赖,将规则从显性变为隐形,能够自适应的产出规则,从而可以适用于更大、更复杂的网络规模。
一个野心更大的知识图谱:KNS
在过往的业界实践中,知识图谱的构建往往受限于运算和存储规模,更加倾向于选择一个特定的垂类领域。但是,学界和业界一直有一个希冀在于:能否构建出一个更大的知识图谱,让它具有更大的信息容量和场景普适性。
对此,「Ta在」给出了自己的答案,提出了知识网络系统(KNS:Knowledge Network System)的概念。我们更倾向于将这一系统视作不同领域、不同维度知识图谱的组合和维度升级。维度的升级,使得整个系统的存储能力和表意性都获得了指数级的提升。

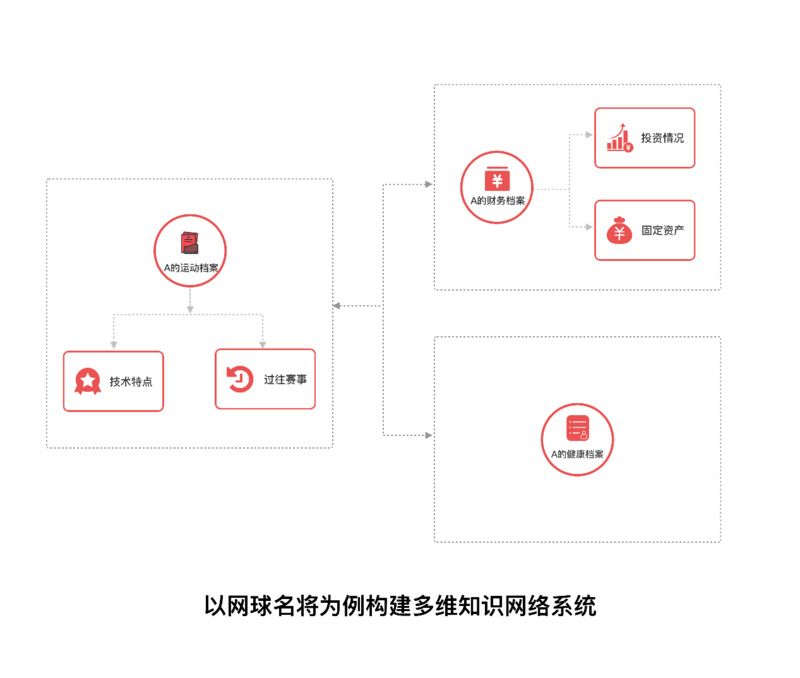
从信息存储层面来看,过往的知识图谱是有边界的,尽管条目数量可以不断扩充,但终归将触碰到领域边界的制约。假设我们构建一个网球知识图谱,其中会涉及到一些网球名将,但是这些信息注定只会存储运动员在网球领域的成绩和特点,而不会包含其更丰富的信息,成为了这些运动员的信息的一个切面。而在知识网络系统中,不同维度的图谱得到了交叉和连接,信息的密度会变得更加稠密。如下图所示,运动员本身的健康、财务信息等单独领域信息共同组成了一个多维知识网络系统,这让我们有了更丰富的应用场景。我们可以基于运动员的健康信息与网球领域的结构信息,进行后续赛事的预测等等。
进一步的,不同于常见的文本信息爬取和存储,知识网络系统还涉及了对于音频、视频、图片等富媒体内容的处理。这种多媒体形态的处理,一方面极大的扩展了信息量,另一方面也显著提升了知识的表意性。同样以网球领域为例,我们能够通过不同比赛录像中同一运动员的赛事片段抽取,更快地观察和分析出运动员的发球特点和技术特征。
更让这一系统富于想象力的是,「 Ta在」引入了演化群体智能算法(ECI:Evolutional Collective Intelligence)来构建知识网络系统。这使得系统不再像是存储在机器里的冷冰冰的数据库,而更像是一个具有动态演变和进化的生命体:演化群体智能算法将用户的沉淀结构化形成内容画像和知识结构,基于智能算法去丰富完善用户的画像,再去搭建用户和内容,用户和用户的关联。在这个自适应的网络生命体里,一个一个节点间能够不断的搭建起连接关系,并基于这种连接关系产生新的交互动作、留下新的内容沉淀、抽取出新的知识结构,往复循环、生生不息。
对比耳熟能详的维基百科,我们不难看出引入了演化群体智能算法后的KNS所具有的极大优势:
- 更低的创造门槛,通过用户不吝于形式和规范的开放创作,由算法进行筛选和结构化抽取。
- 更开放的条目信息,能够借由用户和用户的交互,KNS可以快速的覆盖时效性热点(如网络用词、新闻事件)
- 更具有消费性的知识载体,不局限于图文的富载体能够的描述和传递信息(音频、视频、GIF、短内容等)
- 更好的创作反馈,通过将KNS和社交网络嫁接,能够更好地刺激广泛用户的内容产出意愿,而不仅仅是少量志愿者的提交。
“自生长,广连接,自适应,广沉淀”这便是「 Ta在」围绕人和人、人和信息过载问题给出的解答。对于这一产品所带来的改变,我们乐观其成:就让子弹再飞一会儿。


