英特尔甩出视觉推理新杀器,性能超英伟达,大秀首款云端AI商用芯

芯潮11月13日消息,北京时间今日凌晨2点,英特尔在旧金山举行2019人工智能峰会,推出代号为Keem Bay的下一代Movidius VPU,可用于边缘媒体、计算机视觉和推理应用,并计划于明年上半年上市。
此外,英特尔还在现场展示了Nervana神经网络处理器(NNP),并正式宣告商用。这是英特尔的NNP研发项目对外宣告三年后,正式开始商用交付。
此外,英特尔副总裁兼人工智能产品事业部总经理Naveen Rao、英特尔物联网事业部副总裁兼视觉市场和渠道部门总经理Jonathan Ballon在会上发表演讲,介绍了英特尔最新的AI产品与相关技术进展。
Naveen Rao在现场演讲中谈到,随着英特尔AI产品的更新与发布,AI解决方案的产品组合也将得到进一步的提升与优化,而这也有望在2019年创造超过35亿美元的营收。

01 Movidius Myriad:推理性能提升10倍, 能效为竞品6倍
我们先来说说最新的重量级产品——英特尔Movidius Myriad视觉处理单元(VPU),代号为Keem Bay,其经过优化可在边缘端进行工作负载的推理。

性能方面,与上一代VPU相比,Keem Bay的推理性能提升了10倍以上,能效则可以达到竞品的6倍。
同时,英特尔还介绍到,Keem Bay的功耗约为30W,比英伟达的TX2快4倍,比华为海思的昇腾310快1.25倍。
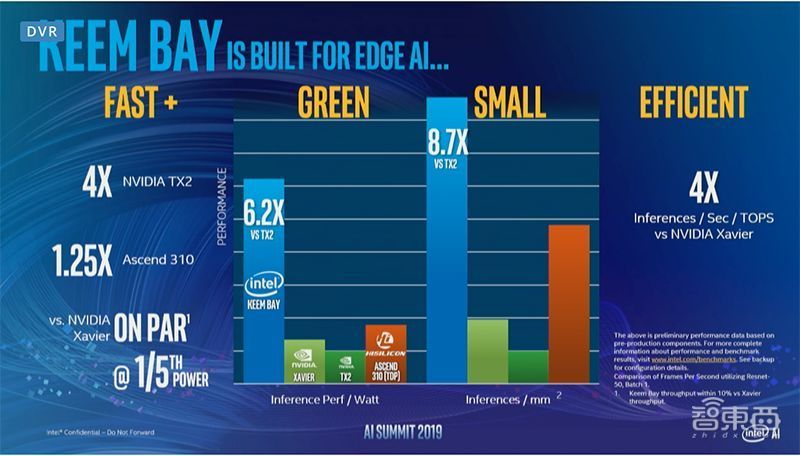
Jonathan Ballon在现场提到,该芯片拥有新的片上存储器架构。同时,Keem Bay每秒提供的Tops推理量是英伟达Xavier的4倍,在充分利用的情况下,该芯片可帮助客户获得50%的额外性能。
“与同类竞品相比,Keem Bay的性能比GPU的性能更好,不仅功率、大小和成本都实现了一定程度的降低,而且还进一步补充了我们完整的产品、工具和服务产品组合。”Jonathan Ballon补充说到。
此外,Keem Bay计划将于2020年上半年上市。

02 Nervana系列:已投入生产,并正式交付商用
今年,英特尔在面向AI推理和AI训练领域,相继推出了NNP-T和NNP-I两款Nervana神经网络处理器,专为大型数据中心而设计。
同时,Nervana神经网络处理器也是英特尔研发的首个针对复杂深度学习的专用ASIC芯片,主要提供给云端和数据中心客户。
实际上,英特尔早在2016年就已对外提出将启动Nervana神经网络处理器的项目研发。然而,英特尔在去年的AI大会中也尚未揭开该系列处理器的神秘面纱,直到今年才面世,现在终于正式交付商用。

Naveen Rao说,作为系统级AI解决方案的一部分,Nervana神经网络训练处理器目前已经投入生产,并已完成客户交付。
其中,NNP-T采用台积电16nm制程工艺,拥有270亿个晶体管,硅片总面积达680平方毫米。
应用上,它具有高度的可编程性,并支持所有主流深度学习框架,如TensorFlow、PYTORCH 训练框架和C++深度学习软件库等。

同时,它还能够实现计算、通信和内存之间的平衡,而且不管是针对小规模群集,还是最大规模的pod超级计算机,它都可以进行近乎线性且极具能效的扩展。

另一方面,NNP-I基于英特尔10nm Ice Lake处理器架构,同样支持所有的主流深度学习框架,在ResNet50上的效率可达4.8 TOPs/W,功率范围为10W到50W之间 。
此外,它具有高能效和低成本,能将传统的AI和多个引擎结合,实现高效率的AI推理工作负载,适合在实际规模下运行高强度的多模式推理。

在Naveen Rao看来,随着AI推理计算不断发展,并逐渐向智能化边缘转移,英特尔的AI竞争优势进一步明显。
“我们非常骄傲,能成为客户背后的算力支柱,我们也将持续用创新和技术来帮助客户布局AI。”Naveen Rao说到,目前,英特尔的许多客户已将其AI解决方案应用于各个层级的设备,部署在本地数据中心和超大规模公有云设施中。
值得一提的是,这两款Nervana神经网络处理器主要面向英特尔的前沿AI客户,如百度和Facebook等,并针对这些企业的AI处理需求进行定制开发。

03 DevCloud:用于边缘设备部署与测试
Naveen Rao说,截至目前,英特尔在无人机、机器人和自动驾驶等设备的边缘计算方面,已实现20%的同比增长。
而今年,在边缘AI方面,英特尔推出了DevCloud for the Edge。
它与OpenVINO工具包结合使用,可让开发人员在购买硬件前,使用现有的工具和框架,免费测试和优化OpenVINO中用于英特尔硬件的模型,例如CPU和FPGA等,进一步帮助开发人员对边缘设备进行AI部署和测试。
Jonathan Ballon在现场演讲中也提到,随着DevCloud for the Edge的发布,客户将能使用英特尔在夏季推出的Deep Learning Workbench工具进行建模和仿真,并可免费将其部署于开发云中的各种硬件配置。
实际上,早在六个月前,DevCloud for the Edge的beta版本就已经推出,截至目前已经有2700个客户在使用。
另一方面,OpenVINO支持从CPU、GPU、FPGA和英特尔Movidius神经计算棒等一系列深度学习加速器。
同时,该工具包在今年早些时候已进行更新,扩展到了计算机视觉应用之外,支持语音和NLP模型。

04 AI已成重要业务,持续强化至强AI推理性能
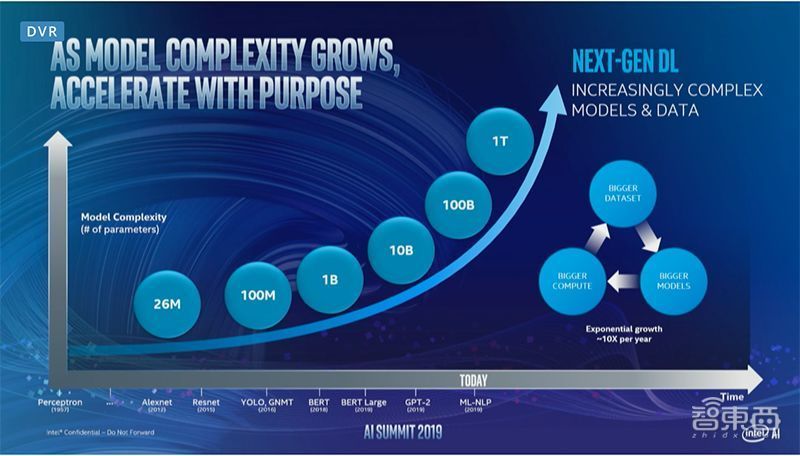
如今,在深度学习的推理和应用方面,都需要十分复杂的数据、模型与技术。
而英特尔的至强可扩展处理器作为面向业界大部分企业和组织的重要平台,已然成为英特尔在推进AI业务发展的重量级产品。
因此,英特尔也将继续通过矢量神经网络指令(VNNI)和深度学习加速技术(DL Boost)等功能优化并改进该平台,以在数据中心和边缘部署中进一步提升它的AI推理性能。
在Naveen Rao看来,随着人工智能的进一步发展,现有的计算硬件和内存都将在未来达到临界点,同时专用型硬件的重要性也愈加明显。
因此,对英特尔来说,利用AI技术来提升业务成果,需要进一步推出涵盖硬件和软件的多种技术组合。
05 结语:加强云端至边缘端AI布局,注重系统级发展
我们可以看到,在各家公司将AI发展路线驶向系统级方向的当下,今年英特尔的AI峰会从AI硬件至软件,从云端到边缘端都进行了几乎全方位的部署与更新。
特别是在目前AI工作负载越来越复杂的环境中,市场对专用AI芯片的需求愈发迫切,英特尔推出的一系列针对深度学习领域的的芯片,不仅更深度地打入AI芯片市场,同时也为当下AI芯片的产品研发和创新提供了新思路。
而未来,随着AI行业的进一步成熟与发酵,英特尔又将为行业带来什么样的惊喜,我们还需拭目以待。


