让大卫雕塑跳舞、蒙娜丽莎说话,英伟达视频合成有如此多“骚操作”

用视频到视频的合成技术生成会跳舞的小哥哥(小姐姐)或自己本人已经不是什么无法解决的问题,但这些方法通常需要大量目标人物的数据,而且学到的模型泛化能力相对不足。
为了解决这个问题,来自英伟达的研究者提出了一种新的few-shot合成框架,仅借助少量目标示例图像就能合成之前未见过的目标或场景的视频,在跳舞、头部特写、街景等场景中都能得到逼真的结果。该论文已被NeurIPS2019接收。
先来看一下合成效果:

用不同示例图像合成的人体跳舞视频。

用英伟达的方法合成的雕塑跳舞视频。

用不同示例图像合成的头部特写视频。

蒙娜丽莎头部合成视频。

街景合成视频。
「视频到视频」合成(简称「vid2vid」)旨在将人体姿态或分割掩模等输入的语义视频,转换为逼真的输出视频。虽然当前vid2vid合成技术已经取得了显著进展,但依然存在以下两种局限:其一,现有方法极其需要数据。
训练过程中需要大量目标人物或场景的图像;其二,学习到的模型泛化能力不足。姿态到人体(pose-to-human)的vid2vid模型只能合成训练集中单个人的姿态,不能泛化到训练集中没有的其他人。
为了克服这两种局限,英伟达的研究者提出了一种few-shotvid2vid框架,该框架在测试时通过利用目标主体的少量示例图像,学习对以前未见主体或场景的视频进行合成。
借助于一个利用注意力机制的新型网络权重生成模块,few-shotvid2vid模型实现了在少样本情况下的泛化能力。他们进行了大量的实验验证,并利用人体跳舞、头部特写和街景等大型视频数据集与强基准做了对比。
实验结果表明,英伟达提出的few-shotvid2vid框架能够有效地解决现有方法存在的局限性。
如下图1(右)所示,few-shotvid2vid框架通过两个输入来生成一个视频:
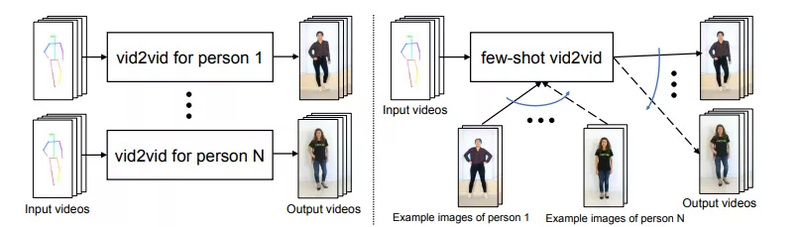
图1:英伟达few-shotvid2vid(右)与现有vid2vid(左)框架的对比。现有的vid2vid方法不考虑泛化到未见过的域。经过训练的模型只能用于合成与训练集中视频相似的视频。英伟达的模型则可以利用测试时提供的少量示例图像来合成新人体的视频。
除了和现有vid2vid方法一样输入语义视频外,few-shotvid2vid还有第二个输入,其中包括测试时可用的目标域的一些示例图像。
值得注意的是,现有的vid2vid方法不存在第二个输入。研究者提出的模型使用这几个示例图像,并通过新颖的网络权重生成机制实现对视频合成机制的动态配置。具体来说,他们训练一个模块来使用示例图像生成网络权重。此外,他们还精心设计了学习目标函数,以方便学习网络权重生成模块。
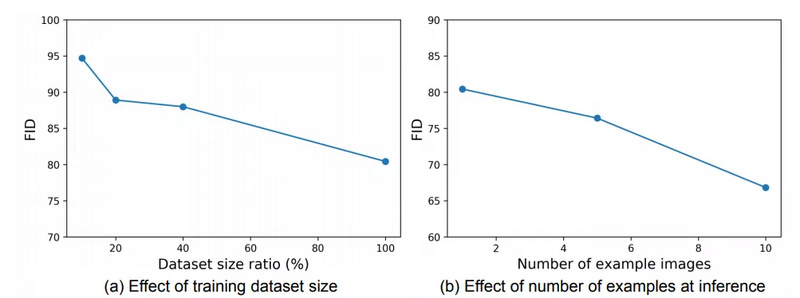
此外,研究者证明了其模型的性能与训练数据集中视频的多样性以及测试时可用示例图像的数量呈正相关。当模型在训练时看到更多不同的域时,可以更好地泛化并处理未见到的域(下图7(a))。当测试时为模型提供更多示例图像时,合成视频的质量会随之提升(下图7(b))。
少样本的视频到视频合成
视频到视频合成旨在学习一个映射函数,该函数可以将输入语义图像的序列,即
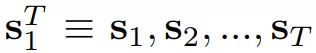
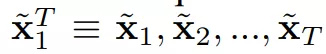
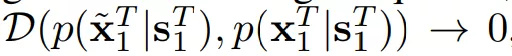

换言之,它基于观察到的Τ+1输入语义图像
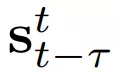
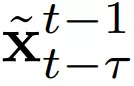
序列生成器F可以通过几种方式进行建模,并且通常选择使用由以下方程得出的matting函数:
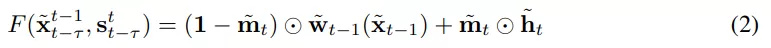
下图2(a)是vid2vid架构和抠图函数的可视图,其中输出图像x_ttilde是通过结合最后生成图像的光流变形版本,即
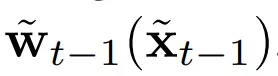
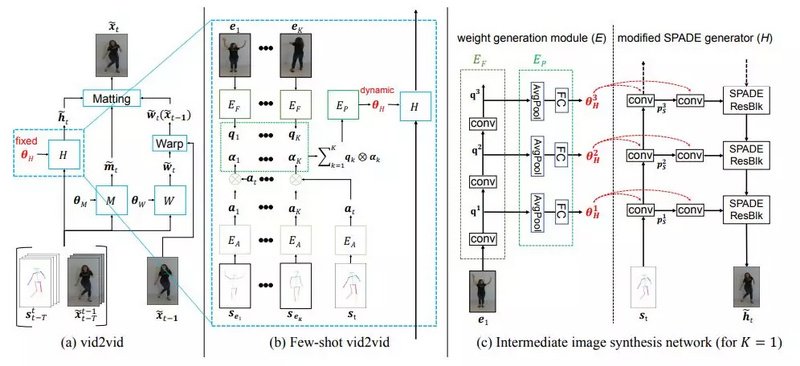
图2:(a)现有vid2vid框架的架构;(b)英伟达提出的few-shotvid2vid框架的架构。
软遮挡映射m˜_t说明了在每个像素位置上如何组合两个图像。简单来说,如果某个像素能在此前生成的帧中被找到,会更有利于从变形图像中复制像素值。实际上是通过神经网络参数化的函数M、W和H生成的:
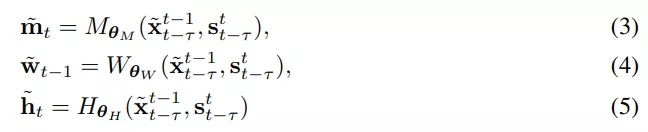
其中,θM、θW和θH是可学习的参数,训练完成后它们会保持固定状态。
Few-shotvid2vid
前面方程1得到的序列生成器希望将新颖的输入转化为语义视频,但现在有一个问题,这样的模型是做不到Few-shot的,它并没有学习到如何合成未知领域的视频。为了令生成器F适应未见过的数据,研究者使得F依赖于额外的输入。
具体而言,研究者给F增加了两个额外的输入参数:即目标领域的K个样本图像{e_1,e_2,...,e_K},以及对应它们对应的语义图像{s_e1,s_e2,...,s_eK}。这样整个生成器就可以表示为如下方程式,它嵌入了少样本学习的属性:
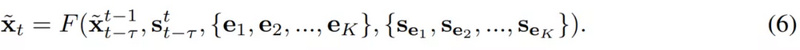
基于注意力的聚合(K>1)
除此之外,研究者还想让E从任意数量的示例图像中提取出模式。由于不同的示例图像可能具有不同的外观模式,而且它们与不同输入图像之间的关联程度也存在差异,研究者设计了一种注意力机制来聚合提取出的外观模式q_1……q_K。
为此,它们构建了一个新的包含若干完全卷积层的注意力网络E_A。E_A应用于示例图像的每个分割图像s_e_k。这样可以得到一个关键向量a_k∈R^(C×N),其中,C是通道的数量,N=H×W是特征图的空间维度。
他们还将E_A应用于当前输入语义图像s_t,以提取其关键向量a_t∈R^(C×N)。接下来,他们通过利用矩阵乘积计算了注意力权重α_k=(a_k)^T⊗a_t。然后将注意力权重用于计算外观表征的加权平均值
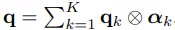
实验结果
下图3展示了在合成人物时使用不同示例的结果。可以看出,英伟达提出的方法可以成功地将动作迁移至所有示例图像中。

图3:人体跳舞视频合成结果可视图。
下图4展示了英伟达提出的方法与其他方法的对比。可以看出,其他方法要么生成有瑕疵的视频,要么无法将动作完全迁移至新视频。

图4:与其他人体动作合成结果的对比。
下图5展示了用不同示例图像合成街景的效果。可以看出,即使使用相同的输入分割图,使用英伟达的方法也能得到不同的结果。

图5:街景视频合成结果图示。
下表1展示了在以上两个任务中,英伟达的方法与其他方法的定量比较。可以看出,英伟达的方法在所有性能指标上都优于其他方法。
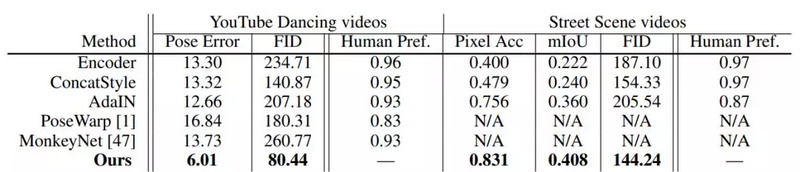
表1:无论是在舞蹈还是街景视频合成任务中,英伟达的方法都优于现有的姿势迁移方法。
下图6展示了在合成人脸时使用不同示例图像的结果。英伟达的方法可以在捕捉到输入视频动作的同时完整保留示例人物特征。

图6:人脸视频合成结果。
研究者假设,更大的训练集可以得到质量更高的合成视频。为了验证这一假设,他们进行了实验。图7(a)显示了改变训练集中的视频数量所得到的性能结果。实验结果支持上述假设。
研究者还通过实验验证了测试时增加示例图像是否可以提升视频合成效果,结果证实了该假设,如下图7(b)所示:
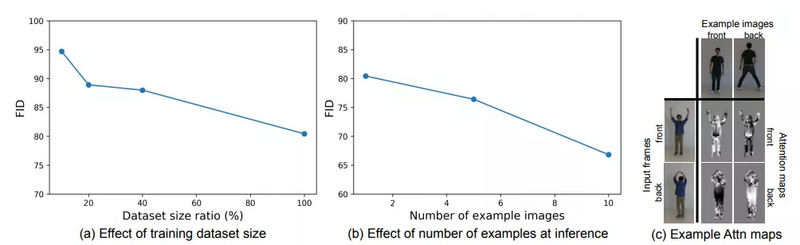
图7:(a)显示,合成视频的质量随着训练集的增大而改善;(b)显示,合成视频的质量与测试时提供的示例图像数量有关。研究者提出的注意力机制可以利用较大的示例集来更好地生成网络权重;(c)给出多个示例图像时注意力图的变化。


